

EMOFM: Ensemble MLP mOdel with Feature-based Mixers for Click-Through Rate Prediction
https://arxiv.org/pdf/2310.04482.pdf
Warning: In this report, the comparison might not be fair enough since the proposed method is designed for the given data in particular while compared methods are not.
In Track one of CTI competition (https://cti.baidu.com), the given Click-Through Rate (CTR) prediction dataset consists of records of hashed features (basic user feature, scene feature, advertisement feature, user session feature and interaction type) and the corresponding labels. Usually, a typical CTR structure paradigm "Embedding + MLP", namely Whole MLPs (WM) in this report, could be implemented as follows.
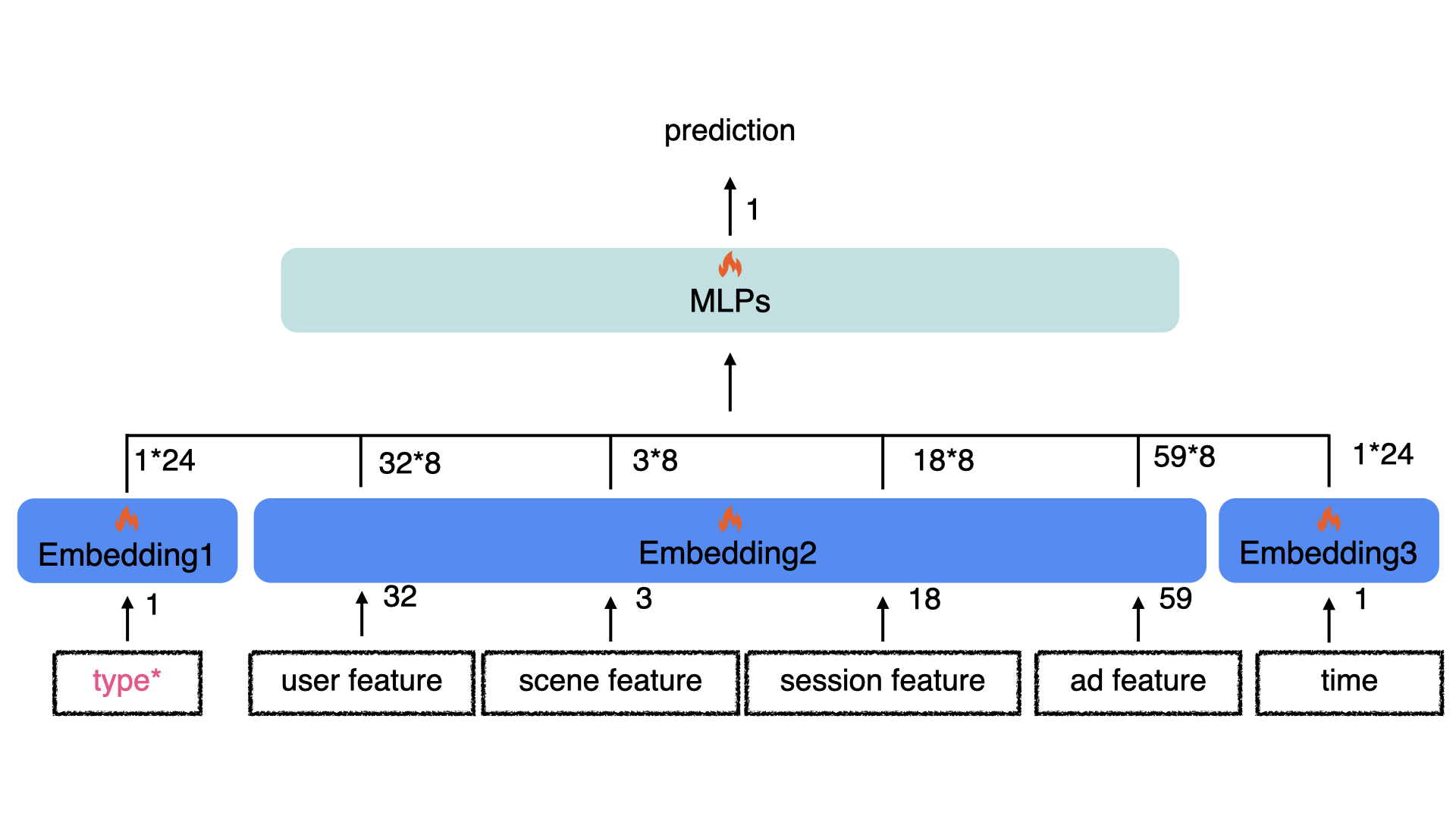
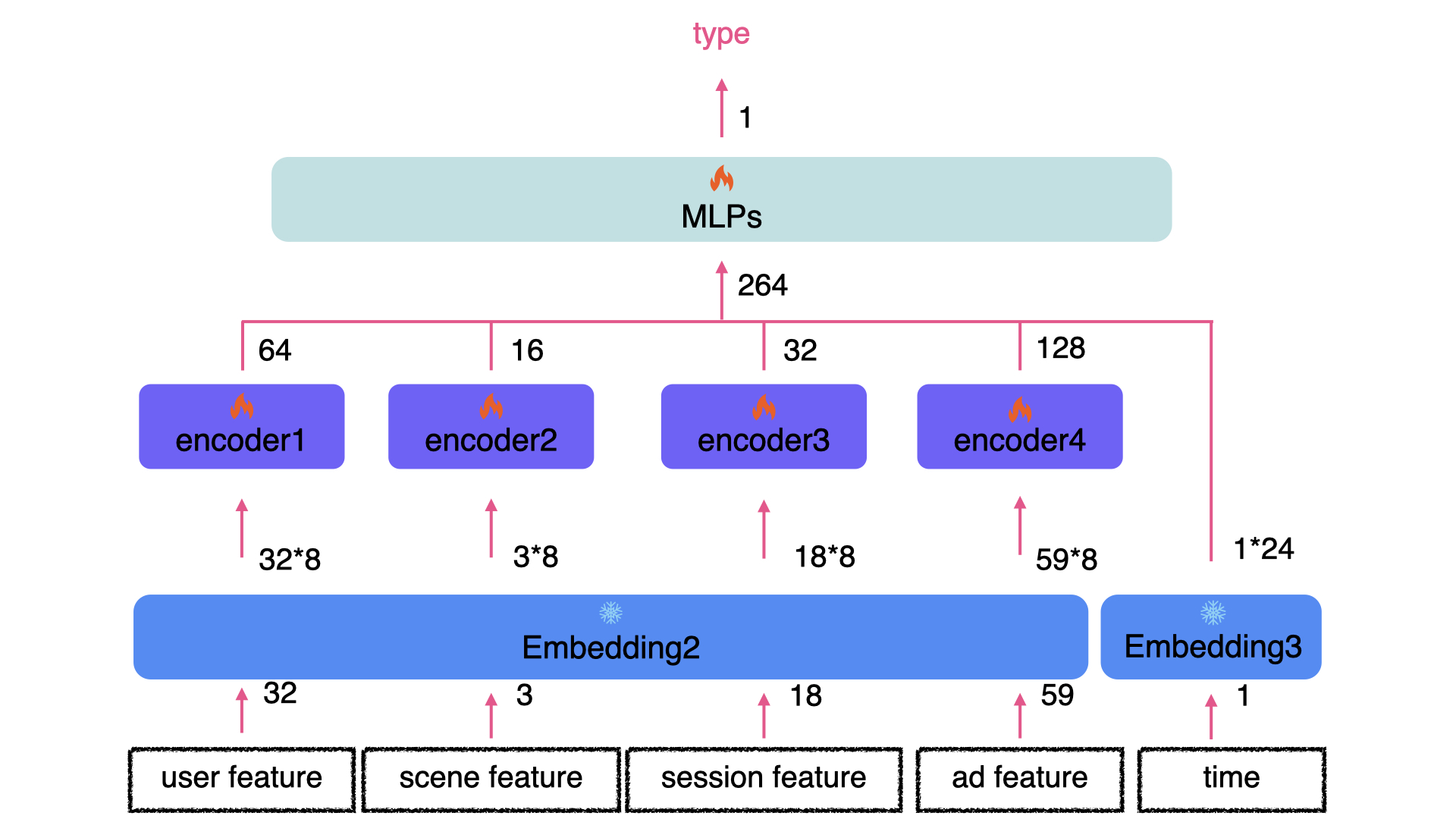
However, interaction types are not available when testing. Hence, we also construct an Auxiliary Model (AM) to predict the interaction types. It is worth noting that we utlize the embedding trained from WM to save the model size. AM is designed as follows.
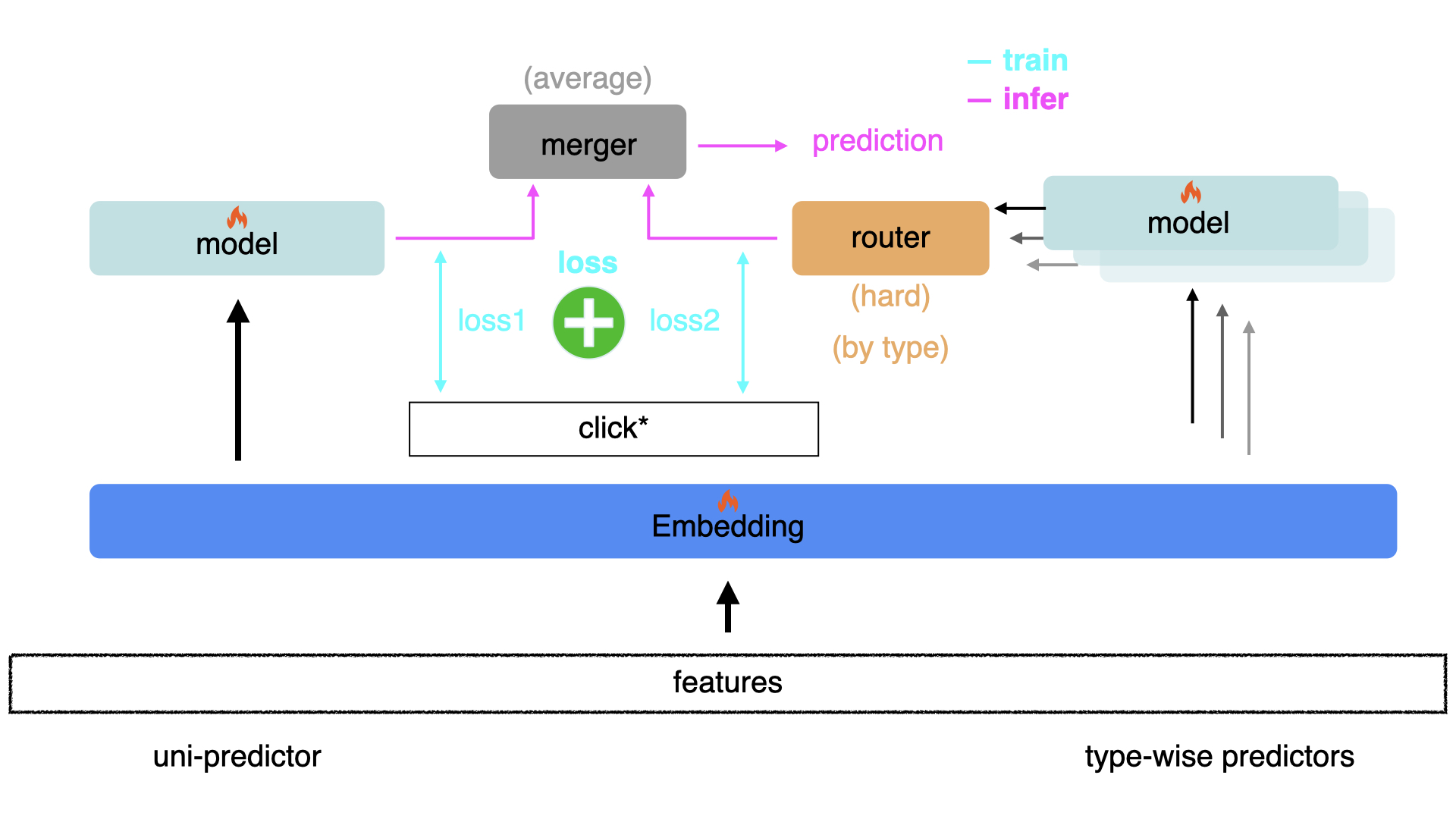
To strengthen the connection of different interaction types and the specific patterns of each interaction type, we ensemble WMs as follows.
Besides, in practical, naive Multi-Layer Perceptrons (MLPs) are not likely to implicitly learn how to fuse features in a good way. Many previous works focus on combining explicit feature fusion and implicit data-driven optimization.
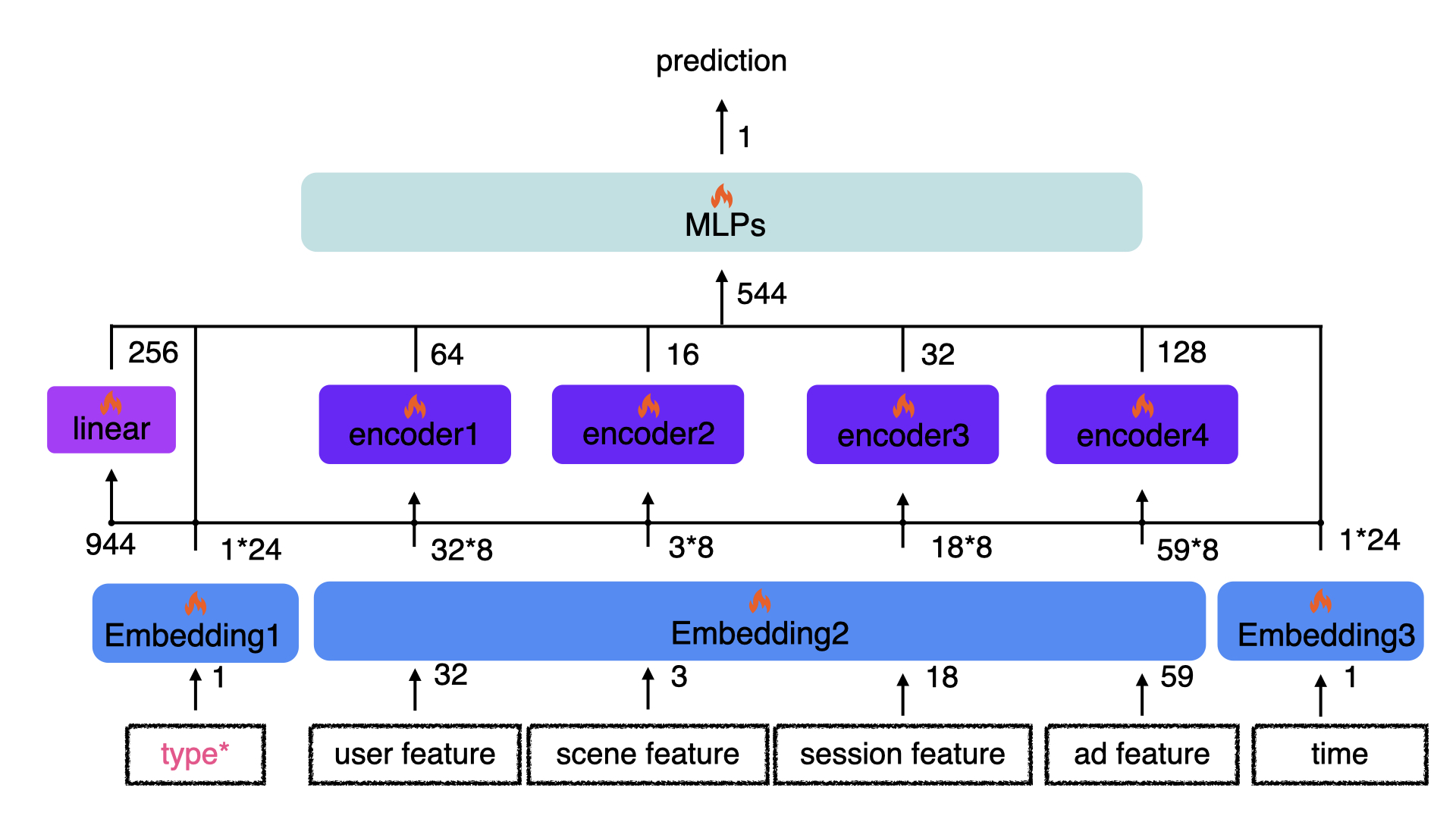
First, we could split the whole MLPs into 2 stages to force the model to learn hierarchically, which is to focus on feature extraction before feature fusion. The corresponding structure, namely Hierarchical MLPs (HM), is shown as follows.
Second, based on the fusion characteristic of cross attention and the efficiency of transformer-based structures, which process feature from different views (e.g. inside-channel and across-channel) in turn, we propose to insert mixers, which is based on cross attention, into the stages. At the first stage, mixers are to fuse features of different fields while at the second stage, mixers fuse features of component models inside the ensemble. The improved model is called Hierarchical MLPs with Mixers (HMM). Field/type-wise mixers are illustrated as follows.
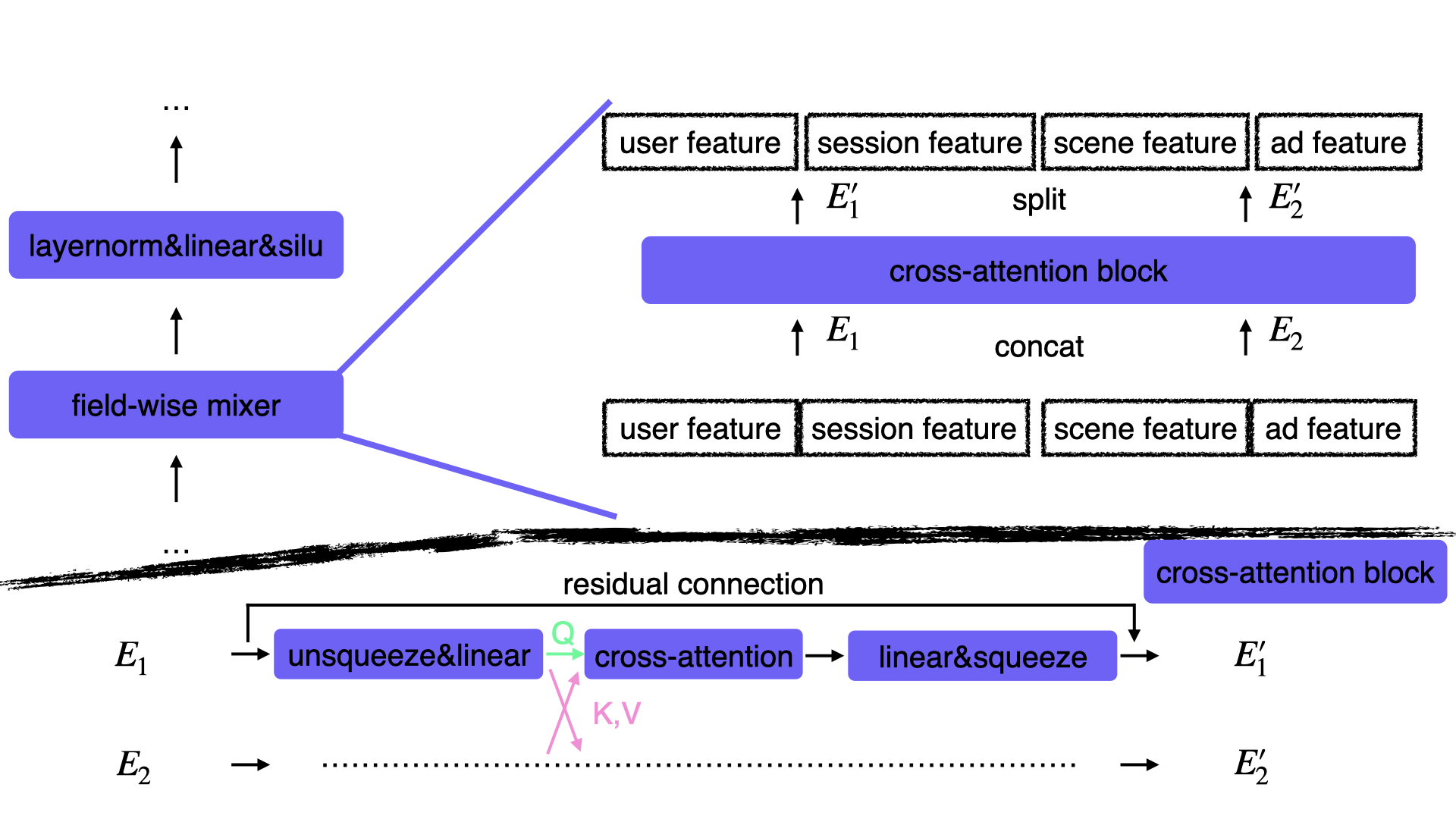
filed-wise mixer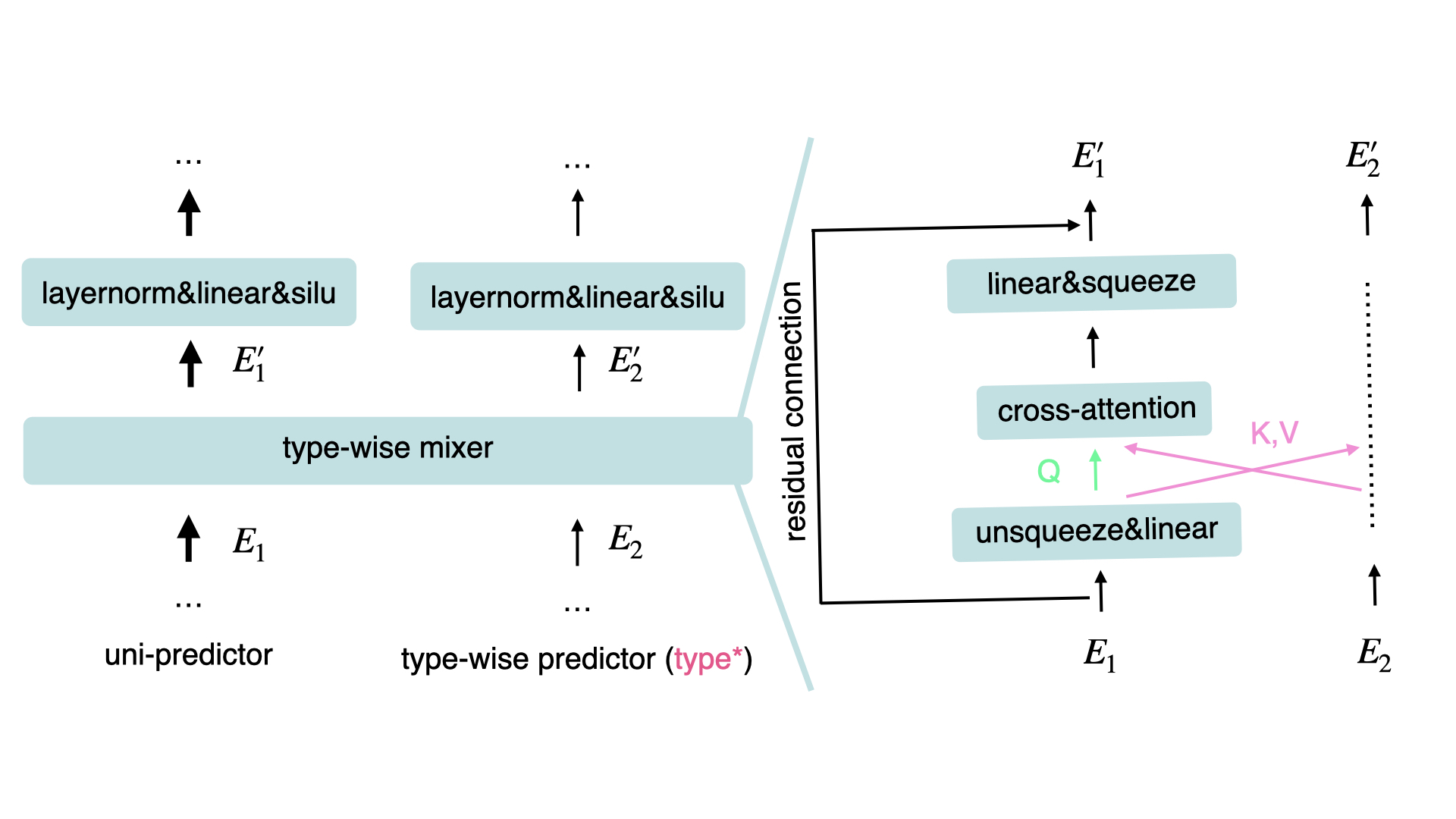
type-wise mixer
Totally, EMOFM is an ensemble of WM, HM and HMM.
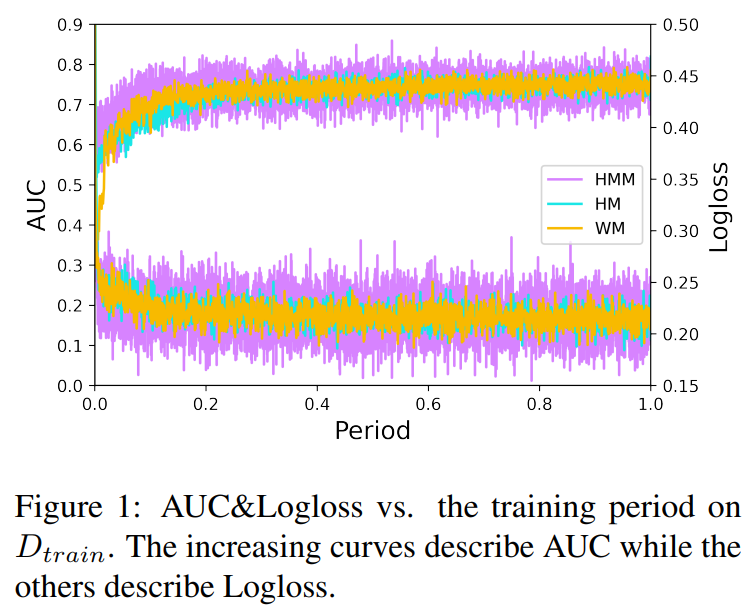
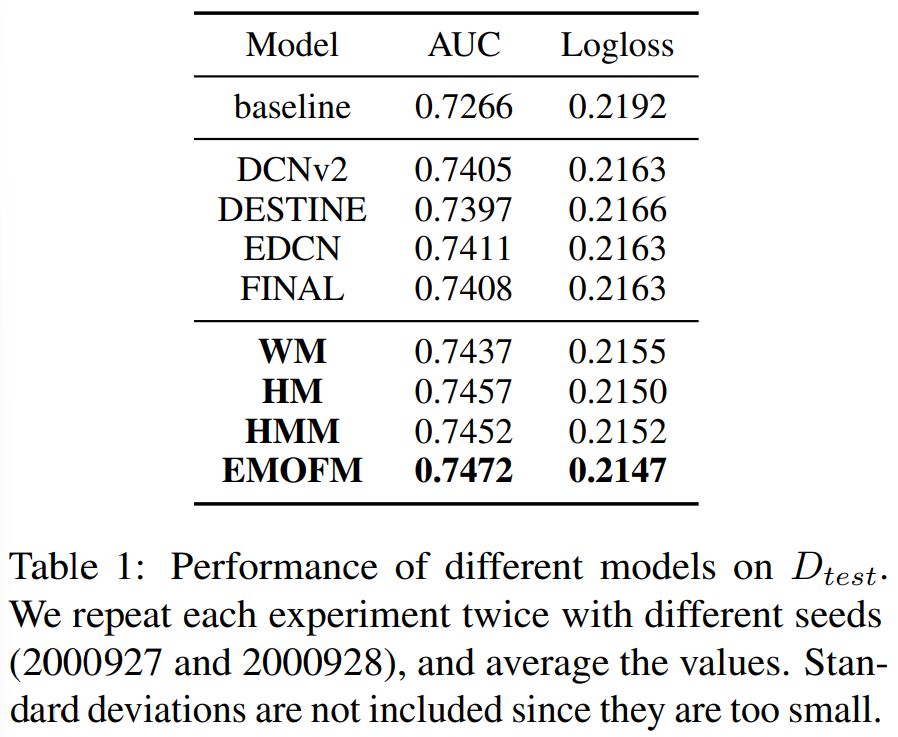
The results of evaluation show that proposed models outperform in the given dataset. The balance of implicit and explicit learning patterns may be a key in CTR prediction. For future work, we believe that how to construct a completely data-driven model which could automatically learn how to handle the balance is meaningful.